Agile Data Modeling: Guide for Developers
Topic: Guides

April 16, 2024
When Is Data Modeling Needed?
As a software developer, I have been dealing with relational databases throughout my professional career since 2001. I started with smaller projects. In 2004, I joined a company that was rolling out ERP systems in large manufacturing enterprises, which required that I learn bigger SQL servers such as MicrosoftSQL and Oracle.
In 2009, I switched to startup development. Startups were mostly web projects developed in the Agile manner - with various changes during the project life.
Startup development brought interesting challenges. Several times, I had requests from customers to prepare a data model before they started a project. By data model, they meant a relational database schema with tables, fields, and references.
The reason why these things were asked was that some people understood the language of relational databases better than user stories, Gherkin, or any other business analysis standards.
It meant when I used plain English to describe the project plan and split the roadmap into sprints, they felt it was less descriptive than a relational data model.
For such customers, it was reasonable to draw what they would understand - a relational database schema.
What Is Data Modeling Software?
There are various tools that allow describing and drawing tables with relations. Here are a few examples:
- https://dbdiagram.io/
- https://dbdiffo.com/
- pgModeler (https://pgmodeler.io/)
- DrawSQL (https://drawsql.app/)
- https://sqldbm.com/
You can choose any tool to your taste - they all are similar with slight differences in the UI and supported SQL versions.
Let’s imagine the following example. The customer wanted a website where the admin could upload books and also create accounts for companies. The companies, in their turn, could have blogs and articles in those blogs. All this content would be posted by managers.
The assignment is simple, but the customer wants a data model. So, let’s use data modeling software and design the following set of tables.
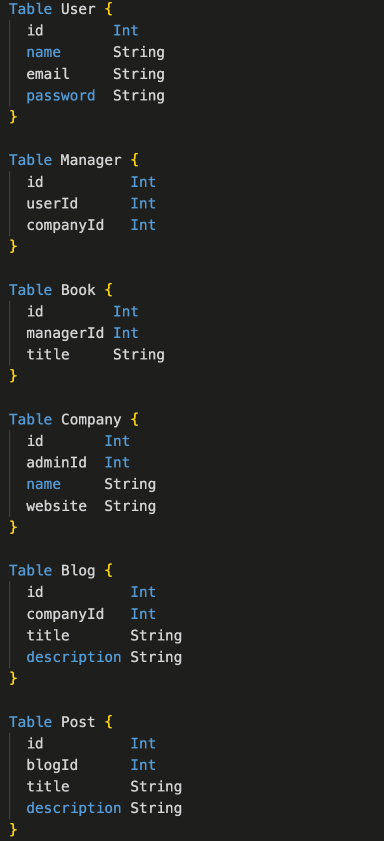
The tables have the following references.
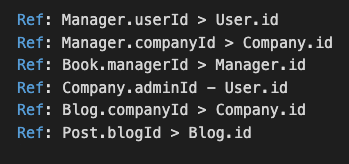
The software draws a picture with the tables, fields, and references which looks this way.

After drawing that, we have a matter to talk about. However, I would not consider this schema final.
Rather, it would only be a matter of discussion. And, probably, a preliminary and simplified approximation of things to come.
What Can Change in an Already-Defined Schema?
In short, anything. The Agile methodology allows changing anything when needed.
However, in real life, it is very hard to change the core of the data model. If there is a set of tables with relations, and the tables are the main part of the project, the architecture is hard to change later on.
This is why we want to think before we create the first version of the database schema. But we also want to leave room for changes.
What can we change in a defined data model?
It is relatively easy to change a one-to-one relationship to a one-to-many relationship. Under one condition: if you have the correct direction in the original one-to-one reference.
Let’s imagine, we have two tables: Order and Payment. They are linked as one-to-one: one order is tied to one payment. Which one should store the id of the other? Should the Order table have a paymentId or Payment have an orderId?
One of the answers is, it depends on your vision of the possible future of this association. How will it change in the future? May an order have multiple payments? May a payment have multiple orders?
If you expect that an order can be covered by multiple payments, then your one-to-one relationship will turn into one-to-many with one order and many payments. Hence, you need to store the field orderId in the Payment table.
Please note that this approach to one-to-one relations is not the only one. There can be other ways of reasoning when approaching one-to-one references, but they go beyond the current topic.
How to Change the Database in the Agile Style?
Usually, the agile development process does not require the whole database architecture to be done before the project starts.
Even if we have thought the data model through and prepared it in data modeling software for the customer, we do not have to push it to production at once.
The usual process implies that the developers work on the user stories one after one - and make relevant changes in the database according to the current user story.
It means the database does not have a table called Book until we get to a user story that says ‘As an admin, I can create a book’. When developers take that story from the backlog, they perform several activities, such as:
- Ask the product owner questions that might help understand the goal.
- Discuss the story and the architecture required with other developers.
- Write tests for the story (if they follow TDD).
- Write database migrations that change the database accordingly.
- Write the code required to cover the business aspects of the story.
Only after this is done and the code is merged and pushed to the server, the Book table appears on the server.
Why Do Developers Need Migrations?
Writing migrations is required to reflect database changes in all servers and local environments of other developers.
Database architecture is synchronized across all computers through migrations.
Without migrations, all project developers would have different databases in their environments. Or, they would have to connect to one single database that would have a monopoly on reality.
I have seen that once. I was invited to review the state of a project which was about to launch. The project infrastructure had many weird aspects and the database was one of them.
The database was created by the product owner and given to the developers before the project even started. Because of that, the development team considered the database as divinely inspired. They put a GraphQL API wrapper around it and queried it from multiple environments.
This way, the database architecture did not come from the backend. It was not driven by user stories and tests. The backend was here and the database was there like the development team did not own it.
At some point, I saw the developers rushing around and messaging everyone who might have access to the database with a question, ‘Was that you who altered that table?’
That was not normal.
Normal is when developers:
- Have requirements written using the business language.
- Write the requirements in the form of automated tests.
- Write the relevant code including database migrations.
- Spread the changes across so that every project participant can apply migrations and have a copy of the same reality.
How to Approach Data Modeling in an Agile Project?
Engineering involves thinking. You need to think. Very often you need to think beforehand.
However, the Agile approach says, you need to think about what you know and throw away thoughts about what you do not know. You just need to care about keeping your work materials easy to scale and maintain.
Therefore, first, you need to create a simple schema that represents real life. Call the tables by names that you can recognize.
If you cannot name an entity, you do not know what it is. Either you understand what it is, or it is a redundant or a fake entity. Tables with names like ProjectUserManager or ContentManagerWithData have red flags on them. You do not call things in real life by such names, do you?
Keep in mind that:
- The initial tables’ decomposition in an Agile project will stay in the project for a long time.
- Usually, tables tend to split - one table becomes several tables.
- Merging multiple tables into one has a lower probability (still is possible).
- Relationships tend to become more complex: one-to-one becomes one-to-many, and one-to-many can become many-to-many.
- Getting rid of many-to-many relationships is hard.
- Getting rid of strange entities with long names is very hard.
Taking into consideration that PostgreSQL and other relational databases do not have good performance when it comes to joining tables with many-to-many relations, I suggest avoiding having many-to-many relations in the first implementation by managing customer’s expectations. Unless you know the real-life entity that represents the intermediary many-to-many table and can call it by name.
Once you have a good database model in mind, you can work on user stories according to the Agile process described in the previous paragraphs.
Do not produce a whole lot of tables prematurely. Let the tables appear in the database as you go through the backlog.
A table should appear in the database only after the relevant concept is introduced in a user story.
Keep your migrations clean. Other developers should be able to apply migrations forward and backward.
All migrations should be followed by automated tests that assure consistency with the entire flow.
With experience, all parts of the Agile process will come together and produce cleaner and healthier code - and a project that is easy to scale and maintain throughout the years.